

There are two types of searches in the Pedagogic Corpus of Lithuanian: simple and advanced.
- Simple Search allows you to search for a word form in the corpus by entering it in the search box. You can use this tool to find instances of a search item in the whole corpus, or you can restrict your search to a particular part of the corpus (spoken or written texts).
Simple search allows you to quickly find the word you want, as well as search by lemma (a basic form of a word that appears as an entry in a dictionary). In this search, the concordance lines will be displayed not only with the exact search item but also with other forms of that item (e.g. If you enter kalba (“language”) in the search box and select the search option lemma, the search results will include all the alternative forms of this word: kalbai, kalbą, kalbų, kalboje, etc.).
You can search for a part of a word by typing an asterisk (*) before or after the part of the word you are searching for, e.g. the search for kalb*, *kalbėti, *kalb* will return the following results:
- kalb*: kalba, kalbos, kalbėti, kalbėjimas, etc.;
- *kalbėti: pakalbėti, nekalbėti, etc.;
- *kalb*: pakalbėti, nekalbu, etc.
When searching for a word or lemma, the search results will be presented in the form of a concordance, i.e. you will see the word or its forms in the minimal context of a single line. The search word or word forms will be highlighted in red and will appear in the center of the concordance line.
In the dropdown menu, you can select the number of lines to be displayed in the main pane of your browser window (from 10 to 200 concordance lines). At the top of the search window, you can see how many concordance lines have been found (“Number of hits”).
Metadata is provided next to each concordance line. By clicking on the sign with the letter i, the following metadata is displayed: participants, situation (for spoken language), text type, genre (for written language), language proficiency level, and language mode (spoken and written language).
The concordance does not contain entire texts that make up the corpus, but only excerpts from them. By clicking on the search word in it (marked in red), you can expand the concordance and see the extended context in a pop-up window (up to 300 characters left and right, if available in the text).
Concordance lines can be sorted by left and / or right context, as well as / or by the search word: for this, hover over the titles Left Context, Search Word, or Right Context and click on any of the selected sorting options. After clicking once, for example, on the option Right Context, the items appearing immediately on the right of the node are grouped alphabetically from Z to A; after clicking on the option a second time, the same results are displayed in alphabetical order from A to Z. The first item to the right of the search word may be not a word but a punctuation mark; thus, punctuation or other characters will also be included when sorting the left or right context alphabetically.
The results can be downloaded (by checking the boxes next to the relevant lines) or by copying individual lines to the clipboard.
- Advanced Search allows you to use all the features of simple search and find some additional options.
With this tool, you can search the whole corpus or select a part of the corpus by proficiency level (A1-A2 or B1-B2) or by language mode (written or spoken). After selecting the written subcorpus, you can further select the text type (coursebooks or non-coursebook texts) and / or the genre of the written texts. Note that there are some differences between the spoken and written subcorpora, and between the subcorpora representing levels A1-A2 and B1-B2 (see Figure 1); as can be seen in Figure 2, the proportions of coursebook and non-coursebook texts vary considerably in different parts of the corpus.
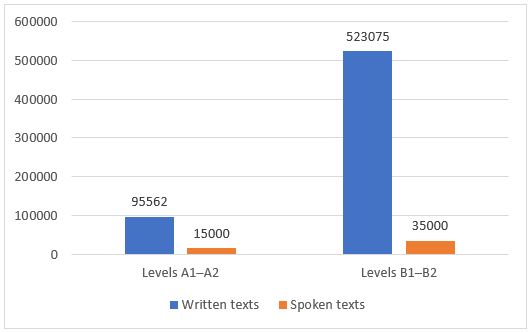
Figure 1. Composition of the Pedagogic Corpus (number of tokens)
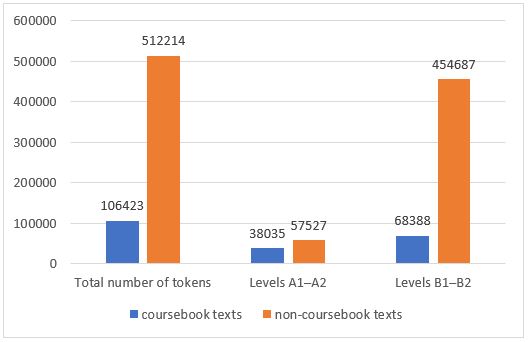
Figure 2. Composition of the written subcorpus of the Pedagogic Corpus (number of tokens)
The distribution of different genres in the written subcorpus is rather uneven (see Table 1); thus, in the categories of some genres, even relatively common words may not be found.
Table 1. Genres in the subcorpus of written language
| Genres (listed alphabetically) | Token number | Percentage |
| Advertisements | 3 077 | 0.50 |
| Advice | 56 630 | 9.15 |
| Announcements | 19 870 | 3.21 |
| Dialogues | 21 366 | 3.45 |
| Documents | 7 990 | 1.29 |
| Fairy tales, legends | 14 864 | 2.40 |
| Folklore | 4 333 | 0.70 |
| Forms and questionnaires | 433 | 0.07 |
| Horoscopes | 20 487 | 3.31 |
| Informational texts | 83 398 | 13.48 |
| Instructions | 10 461 | 1.69 |
| Interviews | 9 261 | 1,50 |
| Jokes | 4 284 | 0.69 |
| Labels | 4 566 | 0.74 |
| Letters, short messages | 22 416 | 3.62 |
| Narratives | 42 489 | 6.87 |
| Other | 21 | 0003 |
| Poems | 143 | 0.02 |
| Popular scientific texts | 113 121 | 18.29 |
| Prose | 67 338 | 10.88 |
| Public signs | 1 744 | 0.28 |
| Recipes, menus | 8 285 | 1.34 |
| Sayings | 601 | 0.10 |
| Schedules, agendas | 158 | 0.03 |
| Slogans | 1 263 | 0.20 |
| Songs | 4 503 | 0.73 |
| Subtitles | 93 941 | 15.19 |
| Tests, activities | 1 005 | 0.16 |
| Wishes, greetings | 589 | 0.10 |
| Total: | 618 637 | 100 |
More information about the Pedagogic Corpus can be found in the following article: Kovalevskaitė J., Rimkutė E. 2020: Mokomasis lietuvių kalbos tekstynas: naujas išteklius lietuvių kalbos besimokantiesiems (Pedagogic Corpus of Lithuanian: a New Resource for Learning and Teaching
Lithuanian as a Foreign Language). Sustainable Multilingualism 17, 201–233.
Since the Pedagogic Corpus is morphologically annotated, the advanced search allows you to search by grammatical features (e.g. part of speech, case, number, verb form, etc.).
The Advanced Search tool allows you to search for one- or two-word forms or their lemmas (you can also enter a form of one word in one search box and the lemma of another word in the other box). It is not necessary to enter specific words; instead, you can select grammatical categories (of one or two search units). You can enter a specific word and select the relevant part of speech (for example, if you enter kalba (“language” or “speak”), you can choose whether to search for a noun or a verb).
The grammatical information is presented in such a way that, when the mode of language is selected, the grammatical categories that are relevant to it (e.g. gender, case, the degree of comparison) are displayed, while the irrelevant categories are inactive and cannot be selected by the user. Therefore, we recommend that you first select the part of speech and then select the required grammatical categories (if needed). For example, if in the drop-down menu of parts of speech, you select the noun category, the categories of gender, number, case, and congruence will be displayed. You can select all or some of these categories, but in such search the categories of tense and person will not be available because they are specific to verbs.
If you search for two words (or other search units), the search unit on the left will appear on the left-hand side in the search results, and the search unit on the right will be displayed on the right. Both search words (or other units) can be next to each other or can appear within 3 words or punctuation marks. The first search unit appears in red, and the second one is displayed in blue.
The corpus is morphologically annotated. Written texts were annotated automatically by using the morphological annotator available at http://semantika.lt/; therefore, some annotation errors may occur. Spoken texts were annotated semi-automatically by using the program CHILDES adapted to the Lithuanian language. Because spoken language is rich in specific forms (contractions, slang, etc.) as well as polysemous forms, some spoken data was annotated manually.
To find clusters in the corpus, such as laba diena (“good afternoon”), iš viso (“in total”), or iš tikrųjų (“actually, really”), you need to enter an element of the cluster and insert an asterisk in the appropriate place. For example, the above-mentioned clusters can be searched for by entering the following items: laba* (note that the search results will include not only laba diena (“good afternoon”), labas vakaras (“good evening”), and labas rytas (“good morning”) but also labas (“hello”) and labai (“very”)), *viso, and *tikrųjų.
Specific features of spoken texts. Due to the specifics of annotation, in spoken texts sentences begin with a lowercase letter. In spoken language, a lemma is considered to be a base form subsuming all the derivational variations of a word. For example, the lemma mama (“mother”) includes not only all the forms of this word, but also the forms of the words mamytė (“mom”), mamukas (“mommy”); the lemma bėgti (“run”) also includes the forms of nebėgti (“not to run”).
Here are some specific symbols used in spoken texts:
@sv – a word of a foreign language;
@k – a swear word;
@d – a dialectal form;
xxx – an incomprehensible word.
The Pedagogic Corpus of Lithuanian was compiled in 2017–2019 thanks to the funding of the project “Lithuanian Academic Scheme for International Cooperation in Baltic Studies”. The corpus contains authentic Lithuanian language texts, selected according to criteria that are relevant to language learners of different proficiency levels. All the texts are classified into levels A1, A2, B1 and B2 according to the Common European Framework of Reference for Languages. The corpus represents both written data and orthographically transcribed spoken data: 111 000 words for levels A1-A2 (96 000 words in the written component and 15 000 words in the spoken component); 558 000 words to represent levels B1-B2 (523 000 words in the written part and 35 000 words in the spoken component). In total, the corpus contains 669 000 words.
The spoken part of the corpus consists of natural conversations recorded in different settings, covering different communicative situations and various social roles of the interlocutors. The spoken data includes face-to-face and telephone service calls in catering establishments (restaurants, cafes, etc.), trading venues (shops, markets, kiosks, bookstores, pharmacies, theatres / cinemas / bus ticket offices, etc.), establishments of different service providers (hairdressers, beauty salons, sewing shops, banks, etc.), as well as conversations at home and in the workplace environment. Some of the texts were taken from the Corpus of Spoken Lithuanian (see http://sakytinistekstynas.vdu.lt/).
The written component consists of two types of texts: (1) texts collected from coursebooks for learners of Lithuanian as a foreign language (hereinafter referred to as coursebook texts; they make up about 17% of the entire written subcorpus), and (2) texts collected from popular scientific and fiction books, news portals, public signs, instructions, announcements, documents, etc. (hereinafter referred to as non-coursebook texts; they amount up to about 83% of the entire written subcorpus). The level of coursebook texts was generally clear, and non-coursebook texts were automatically classified using machine-learning models (the level of these texts was determined with 60% accuracy).
Coursebook and non-coursebook texts are classified into 29 genres (dialogues, narratives, instructional texts, etc.) and correspond to four groups according to communication goals (informative, popular scientific texts, appellative, and imaginative). The most common genres of coursebook texts are popular scientific texts, narratives, and dialogues (in total, these three genres amount up to about 78% of all coursebook texts). Non-coursebook texts comprise subtitles, informative texts, popular scientific texts, prose, and advisory texts (in total, these texts constitute about 73% of all non-coursebook texts).
The corpus was developed by researchers from the Center of Computational Linguistics, the Center of Intercultural Communication and Multilingualism Research, as well as representatives of other departments of Vytautas Magnus University: Erika Rimkutė (Research Team Coordinator), Laura Kamandulytė-Merfeldienė (coordinator of the activities related to the development of the spoken subcorpus), Gabrielė Aleksandravičiūtė, Laimutė Anglickienė, Giedrė Barkauskaitė, Agnė Bielinskienė, Loïc Boizou, Gintarė Grigonytė, Jolanta Kovalevskaitė, Gabrielė Virbickienė.
Web Developer: Petras Pauliūnas
List of sources used for the written component of the Pedagogic Corpus of Lithuanian
1. Coursebooks
Čubajevaitė L., Ruzaitė J., Lemanaitė G. 2014: Takas. Kaunas: Vytauto Didžiojo universitetas, Vilnius: Versus aureus.
Džežulskienė J. 2005: Lietuvių kalba kitakalbiams. Kaunas: Technologija.
Džežulskienė J. 2014: Kalbu lietuviškai. Retrieved from: https://www.easylithuanian.com/
Hilbig I., Stumbrienė V., Vaškevičienė L. 2009: Trumpas lietuvių kalbos kursas pradedantiesiems. Vilnius: Vilniaus universiteto leidykla.
Hilbig I., Migauskienė R., Našlėnaitė-Eberhardt V., Petrašiūnienė E., Tamošaitienė A., Valančiauskienė A., Vaškevičienė L. 2010: Sveiki atvykę! Vilnius: Vilniaus universiteto leidykla.
Jakaitienė E. 1994: Lietuviškai apie Lietuvą. Vilnius: Alma Littera.
Kruopienė I. 2009: 10 žingsnių. Trumpas lietuvių kalbos kursas pradedantiesiems. Vilnius: Vilniaus universitetas.
Migauskienė R. 2014: Žingsnis. Vilnius: Eugrimas.
Migauskienė R., Vaisėtaitė E. 2014: Žodis žodį veja. Vilnius: Eugrimas.
Narbutas E., Pribušauskaitė J., Ramonienė M., Skapienė S., Vilkienė L. 2002: Slenkstis. Strasbourg: Council of Europe Press.
Pribušauskaitė J., Ramonienė M., Skapienė S., Vilkienė L. 2000: Aukštuma. Strasbourg: Council of Europe Press.
Ramonienė M., Pribušauskaitė J., Vilkienė L. 2006: Pusiaukelė. Europos Taryba.
Ramonienė M., Vilkienė L. 1998, 1999: Po truputį (mokytojo ir mokinio knygos). Vilnius: Baltos lankos.
Stumbrienė V., Kaškelevičienė A. 2002: Nė dienos be lietuvių kalbos. Vilnius: Gimtasis žodis.
Vaškevičienė L., Kutanovienė E., Valančiauskienė A. 2015: Pažiūrėk! Paklausyk! Pasakyk! Vilnius: Eugrimas.
2. Non-coursebook texts
2.1. Informative texts
Different texts from DELFI.lt, 2014–2016.
Conversations about life recorded in 2008 (with Rasma Aniulytė, Asta Ziutelytė, Stasė Venčaitienė). Manuscript of Ethnology, Department of Cultural Studies, Vytautas Magnus University.
Diary written in 2009. The manuscript was submitted by Klara Liebutė. Manuscript of Ethnology, Department of Cultural Studies, Vytautas Magnus University.
Dictation for first graders, second graders, third graders, and fourth graders. Retrieved from: http://mudubudu.lt.
Documents (information on how to open a bank account, receive unemployment or maternity benefits, and a housing loan; who is covered by compulsory health insurance; who is issued a residence permit in Lithuania, etc.); collected in 2018 from different government websites.
Emails. Personal data of the research team.
Labels, brief descriptions of goods collected in 2018 from different websites.
Horoscopes collected in 2010 from different websites.
Instructions (information on the use and maintenance of various household appliances, e.g. TV sets, washing machines, irons, etc.; house rules explicating what can and cannot be done in a household); collected from various websites in 2018.
Personal ads collected in 2005 from newspapers and magazines “Lietuvos rytas”, “Atleisk”, “Viltys ir likimai”, “Antra pusė”, “Gyvenimiškos istorijos”.
Text messages; online forum posts. Personal data of the research team.
Public signs collected in 2018 from medical, catering, and cultural institutions, public transport, and other public places.
2.2. Popular scientific texts
Aleksaitė I., Jazbutytė N. 2008: Geros manieros – pusė karjeros. Vilnius: Mintis.
Aleksaitė I., Jazbutytė N. 2010: Prie stalo, ant stalo, po stalu: šventė kiekvienuose namuose. Vilnius: Mintis.
Flintas, Flinto bumas (žurnalas), 2008. Kaunas: Jūsų Flintas.
Gudzinskas Z. 2010: Kur uogauti Lietuvoje. Kaunas: Šviesa.
Heiney P. 2008: Ar karvės gali nulipti laiptais? Atsakymai į keblius klausimus. Vilnius: Mintis.
Imbrasienė B. 2010: Lietuvių kulinarijos paveldas. Vilnius: Baltos lankos.
Iršėnaitė R. 2010: Kur grybauti Lietuvoje. Kaunas: Šviesa.
Kaunas Tourism Information Center (descriptions of excursions, places of interest, holidays, and other information), 2017. Retrieved from: https://visit.kaunas.lt/lt/.
Travel descriptions collected in 2017. Retrieved from: http://www.kiveda.lt/.
Travel descriptions collected in 2017. Retrieved from: https://www.gruda.lt/.
Travel descriptions collected in 2017. Retrieved from: https://www.makalius.lt/.
Klaipėda Tourism Information Center (descriptions of excursions, places of interest, holidays, and other information). Retrieved from: http://www.klaipedainfo.lt/.
Mergaitė (magazine), 2008. Vilnius: Egmont Lietuva.
Penki: užduotys, juokai, konkursai, prizai. UAB Presa, 2017. No. 2.
Conversations about Kaunas recorded in 2009 (with Justė Vasilionytė-Stašaitienė). Manuscript of Ethnology, Department of Cultural Studies, Vytautas Magnus University.
Saugaus pirmoko pasas, 2012. Demokratinių iniciatyvų centras.
Semaška A. 2007: Lietuvos keliais. Turisto žinynas. Vilnius: Algimantas.
Spalvink: Ledo šalis. Dysney, 2017, No. 2, July–September.
SU P.E.R. (magazine), 2008. Kaunas: Jūsų Flintas.
Texts received from teachers of Lithuanian as a foreign language.
Vilnius Tourism Information Center (descriptions of excursions, places of interest, holidays, and other information), 2017. Retrieved from: http://www.vilnius-tourism.lt/.
Žilinskas R. 2010: Kur žvejoti Lietuvoje. Kaunas: Šviesa.
2.3. Appellative texts
Advertising and non-advertising slogans collected in 2017 from websites of different companies.
Social advertisements collected in 2008 from roadside billboards, internet, and television.
2.4. Imaginative texts
Ambrukaitis J., Pobrein V. 2001: Lietuvių kalba 5. Antroji knyga. Kaunas: Šviesa.
Jokes collected in 2009. Manuscript of Ethnology, Department of Cultural Studies, Vytautas Magnus University.
Beresnevičius G. 2005: Pabėgęs dvaras. Vilnius: Lietuvos rašytojų sąjungos leidykla.
Dzvankauskaitė I. 2009: Lietuvių šiuolaikinių populiariųjų jaunimo dainų kalbinės ypatybės. BA Thesis. Kaunas: Vytauto Didžiojo universitetas (the appendix containing songs was used).
Gimberis J. 2011: Jūs turite teisę tylėti. Vilnius: Versus aureus.
Gudonytė K. 2012: Ida iš šešėlių sodo. Vilnius: Tyto alba.
Inis L. 2012: Atsidaro metų durys. Kaunas: Arx reklama.
Kasparavičius K. 2009: Baltasis dramblys. Tolimųjų kraštų istorijos. Vilnius: Nieko rimto.
Kunčinas J. 2006: Baltųjų sūrių naktis. Vilnius: Gimtasis žodis.
School anthems collected from various websites in 2000–2012.
Proverbs and Sayings: An Electronic Collection, 1998–2005. Retrieved from: http://www.aruodai.lt/patarles/.
Skeris R. 1990: Ką žmonės dirba visą dieną? Vilnius: Vyturys.
Subtitles of feature films. Retrieved from: http://www.subtitrai.net.
Šepetys R. 2011: Tarp pilkų debesų. Vilnius: Alma littera.
Šimaitis V. 2008: Komunalinis bliuzas. Vilnius: Vaga.
Vincė L. 2008: Lenino galva ant padėklo. Amerikietės studentės dienoraštis, rašytas paskutiniais Sovietų Sąjungos gyvavimo metais. Vilnius: Lietuvos rašytojų sąjungos leidykla.
Some of the frequency lists provided here are based on the entire Pedagogic Corpus of Lithuanian (henceforth, pedagogic corpus), while some of them are based on the written or spoken component. In cases where there are no significant differences between the subcorpora or where it was not possible to compile separate lists, frequency lists for the whole corpus are provided.
Most frequency lists include items used five times or more in the pedagogic corpus. Rarer cases have been excluded since they tend to contain spelling or annotation errors and foreign words. However, the frequency lists of pronouns, numerals, conjunctions, and other non-inflected words contain all the items because they are limited in number. The frequency lists of content words do not include foreign words or abbreviations that are not common in Lithuanian even if they occur in the corpus more than five times.
The lists can be downloaded as .xlsx files.
The frequency lists were generated by Loïc Boizou; they were processed and finalised by Erika Rimkutė.
- List of lemmas for the whole Pedagogic Corpus
- Word forms list for the whole Pedagogic Corpus
- List of lemmas for levels A1-A2
- List of word forms for levels A1-A2
- List of lemmas for levels B1-B2
- List of word forms for levels B1-B2
- List of lemmas for the written component
- List of word forms for the written component
- List of lemmas for the spoken component
- List of word forms for the spoken component
- List of nouns for the whole corpus
- List of verbs for the whole corpus
- List of adjectives for the whole corpus
- List of numerals for the whole corpus
- List of pronouns for the whole corpus
- List of adverbs for the whole corpus
- List of conjunctions for the whole corpus
- List of particles for the whole corpus
- List of prepositions for the whole corpus
- List of interjections and onomatopoeia for the whole corpus
v.1.3