

There are two types of searches in the Lithuanian Learner Corpus (LLC): simple and advanced.
1. Simple search allows you to quickly search for a word form in the corpus by entering it in the search box. You can use this tool to find instances of a search item in the whole corpus, or you can restrict your search to a particular part of the corpus (spoken or written texts). The search results provide the frequency of the search item and the context where it occurs (concordance lines).
You can search for a specific word form or a part of a word by typing an asterisk (*) before or after the part of the word you are searching for, e.g. the search for važiuo*, *važiuoti, *važ* (‘go’), will return the following results:
- važiuo*: važiuoju, važiuoja, važiuodavo, važiuosime, važiuokite, etc.;
- *važiuoti: nuvažiuoti, parvažiuoti, nevažiuoti, etc.,
- *važ*: parvažiavau, privažiuos, nevažiuok, etc.
Such a search is relevant when you want to find different forms of a word and see the complete diversity of them in the LLC.
When searching for a word, the search results will be presented in the form of a concordance, i.e. you will see the word or its forms in the minimal context of a single line. The search item will be highlighted in red and will appear in the center of the concordance line.
In the dropdown menu, you can select the number of lines to be displayed in the main pane of your browser window (from 10 to 200 concordance lines). At the top of the search window, you can see the raw frequency of the search item (“Number of hits”) and the relative frequency per 100,000 words.
Metadata is provided next to each concordance line. By clicking on the sign with the letter i, the following metadata is displayed: language proficiency level, first language, genre, type of the task, and use of reference tools.
The concordance does not contain entire texts that make up the corpus, but only excerpts from them. By clicking on the search word in it (marked in red), you can expand the concordance and see the extended context in a pop-up window (up to 300 characters left and right, if available in the text).
Concordance lines can be sorted by left and / or right context, as well as / or by the search word: for this, hover over the titles Left Context, Search Word, or Right Context and click on any of the selected sorting options. After clicking once, for example, on the option Right Context, the items appearing immediately on the right of the node are grouped alphabetically from Z to A; after clicking on the option a second time, the same results are displayed in alphabetical order from A to Z. The first item to the right of the search word may be not a word but a punctuation mark; thus, punctuation or other characters will also be included when sorting the left or right context alphabetically.
The results can be downloaded (by checking the boxes next to the relevant lines) or by copying individual lines to the clipboard.
2. Advanced Search allows you to use all the features of simple search and find some additional options. You can search the entire corpus or select a relevant subcorpus by language level (A1, A2, B1, or B2) or by mode (written or spoken).
You can search for a word form by selecting different speaker characteristics (e.g. L1, foreign language(s) spoken, home language(s), age, education, etc.) and/or search by error type, type of the text, or any other parameter coded in the corpus metadata.
You can select all or some of the search parameters.
Search by error type
The LLC is normalized, i.e. when annotating errors, non-existent forms and forms deviating from the standard native-speaker use were corrected by entering a regular form and marking the type(s) of error. Therefore, when performing the search by error type, you can find irregular, or deviant, language variants of the search item.
Here are the types of errors that are annotated in the LLC:
- orthographic (in the written LLC) or pronunciation (in the spoken LLC),
- syntactic, and
- lexical errors.
Search for collocations
To study word collocations (that is, words co-occurring with the search item), concordance lines should be examined.
The Lithuanian Learner Corpus (LLC) was compiled in 2017–2019 within the framework of the project “Lithuanian Academic Scheme for International Cooperation in Baltic Studies”. The corpus consists of authentic texts produced by non-native speakers of Lithuanian learning the language in different institutions in different countries (such as Lithuania, Sweden, Germany, China, and other countries).
All the LLC texts are classified into levels A1, A2, B1, and B2 according to the Common European Framework of Reference for Languages. The texts are divided into these four levels of proficiency on the basis of diagnostic tests used in the institution where the learner was based or the amount of Lithuanian language contact hours received in formal education.
The corpus consists of written texts and orthographically transcribed spoken data:
- 103,148 words for level A1 (81,339 words in the written component and 21,809 words in the spoken component);
- 99,359 words to represent level A2 (85,158 words in the written part and 14,201 words in the spoken component);
- 64,400 words for level B1 (39,558 words in the written part and 24,842 words in the spoken part);
- 51,734 words for level B2 (24,211 words in the written data and 27,523 words in the spoken component).
In total, the corpus contains 318,641 words.
Below you will find more detailed information about the LLC structure according to different parameters.
1. Language mode
The corpus consists of written and spoken texts, but written texts dominate.
Table 1. Language mode
| Mode | Number of words | % |
| Written | 240,299 | 75 |
| Spoken | 78,342 | 25 |
| Total | 318,641 |
The length of texts varies from 6-7 to 1,964 words. The average length is 94 words.
2. Language level
In the subcorpora of levels A1 and A2, spoken language constitutes 21% and 14% of the data respectively, but there are more spoken texts in the B1 component and especially the B2 subcorpus. Such distribution is partly due to the different speaking skills of Lithuanian language learners at different levels. Also, advanced language users were more inclined to speak than to write texts.
Table 2. Distribution of the LLC data by language level and mode
| Language level | Written language | % | Spoken language | % | Total number of words |
| A1 | 81,339 | 79 | 21,809 | 21 | 103,148 |
| A2 | 85,158 | 86 | 14,201 | 14 | 99,359 |
| B1 | 39,558 | 61 | 24,842 | 39 | 64,400 |
| B2 | 24,211 | 47 | 27,523 | 53 | 51,734 |
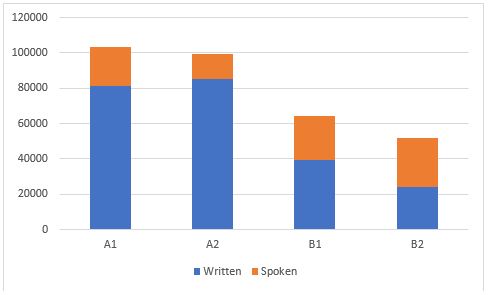
Figure 1. Composition of the LLC data by language level and mode (number of words)
Table 3. Number of texts by language level and mode
| Language level | Written | % | Spoken | % | Total |
| A1 | 1,015 | 92 | 88 | 8 | 1,103 |
| A2 | 613 | 93 | 50 | 7 | 663 |
| B1 | 324 | 86 | 54 | 14 | 378 |
| B2 | 140 | 73 | 53 | 27 | 193 |
The disbalance between the lower and upper levels results from the fact that there are relatively few learners of Lithuanian who reach levels B1 and B2.
3. Genres
Learner texts in the LLC are classified into 11 genres.
Table 4. Genres represented in the LLC
| Genre | Number of words | % |
| Written texts | ||
| Descriptive text | 165,342 | 62.0 |
| Dialogue | 46,870 | 17.6 |
| Letter | 31,552 | 11.8 |
| Argumentative text | 11,183 | 4.2 |
| Creative writing | 5,919 | 2.2 |
| Narrative | 5,338 | 2.0 |
| 498 | 0.2 | |
| Total in written texts: | 266,702 | 100 |
| Spoken texts | ||
| Interview | 35,516 | 68.4 |
| Semi-prepared interview | 9,131 | 17.6 |
| Presentation | 6,363 | 12.3 |
| Discussion | 929 | 1.8 |
| Total in spoken texts: | 51,939 | 100 |
It is important to note that dialogues in the written subcorpus are different from conversations (interviews) in the spoken subcorpus. Written dialogues only mimic a live conversation but are in fact fictional conversations between fictional conversation participants, while interviews in the spoken part are live conversations (usually between a teacher and a learner and sometimes between two or more learners). In the spoken subcorpus, the interview is distinguished from the non-spontaneous interview, as in some cases learners had the opportunity to prepare in advance for the conversation.
The distribution of different genres in the written subcorpus is rather uneven (see Table 4); thus, in the categories of some genres, even relatively common words may not be found, and the variety of errors may be highly limited.
4. Type of the task
The corpus represents several types of tasks: homework and classwork, as well as assessment tasks (intermediate tests in the classroom, exams, and diagnostic tests). In cases where the learner profiles (questionnaires filled out for the LLC texts) lacked information about the type of the task, the texts were assigned to the category “Unknown”.
Table 5. Distribution of the LLC data by the type of the task
| Type of the task | Number of words | % |
| Homework | 120,300 | 38 |
| Exam | 89,409 | 28 |
| Test | 32,793 | 10 |
| Classwork | 26,573 | 8 |
| Diagnostic test | 11,422 | 4 |
| Unknown | 38,144 | 12 |
5. Use of reference tools
For a large part of the LLC texts, reference sources such as grammar books, dictionaries, or online resources were not used (48% of the texts). However, as a large number of written texts consist of homework assignments, students used resources for them, as well as for some classwork assignments: such texts account for 39% of all the data (see Table 6).
Table 6. Composition of the LLC in relation to the use of reference tools
| Were references sources used? | Number of words | % |
| Yes | 154,133 | 39 |
| No | 125,640 | 48 |
| Unknown | 38,868 | 13 |
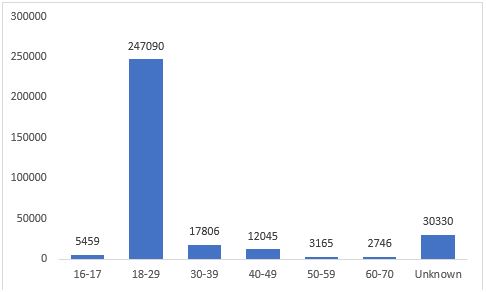
Figure 2. Distribution of the LLC data by age
7. Education
The majority of learners completed secondary education, and the number of learners with higher education is smaller.
Table 7. Distribution of the LLC data by educational level
| Education | Number of words | % |
| Secondary | 165,946 | 52.1 |
| Higher | 100,419 | 31.5 |
| Unknown | 50,641 | 15.9 |
| Other | 1,564 | 0.5 |
8. Linguistic profile
The data in the LLC represents a great diversity of learner profiles in terms of their first language(s) (L1), the language(s) of their parents, and home language(s). The languages spoken by the learners represented in the LLC can be seen in the dropdown menus of the corpus.
The top ten most common L1s are Georgian, Latvian, Russian, Chinese, Japanese, German, Czech, English, French, and Ukrainian. A considerable proportion of learners are bilingual or multilingual.
The most common home languages include Russian, Latvian, Chinese, and German. Almost all learners speak at least one foreign language, and most of them can speak more than one.
The data representing speakers who do not speak any foreign language constitutes only 1,976 words. The top three most frequent foreign languages indicated by learners include English, Russian, and French. The maximum number of foreign languages spoken by a single speaker is 11.
9. Error types
The LLC is annotated for language errors. This was achieved by using the TEITOK programme developed by Maarten Janssen (2014-, http://www.teitok.org/). TEITOK is “a web-based framework for corpus creation, annotation, and distribution, that combines textual and linguistic annotation within a single TEI based XML document” (Janssen 2016; for more detailed information on the TEITOK function of error tagging, see Del Rio 2016).
Following the model applied in other TEITOK-based corpora, the annotation of deviant language forms in the LLC was done at the token level and distinguishes the following types of errors:
- In the written LLC, syntactic, lexical, and orthographical errors are distinguished,
- In the spoken LLC, syntactic, lexical, and pronunciation errors are distinguished.
More information about error annotation in the LLC can be found in the following paper: Ruzaitė, Jūratė; Dereškevičiūtė, Sigita; Kavaliauskaitė-Vilkinienė, Viktorija; Krivickaitė-Leišienė, Eglė. Error tagging in the Lithuanian learner corpus // Human language technologies – the Baltic perspective: proceedings of the 9th international conference, Baltic HLT, Kaunas, Vytautas Magnus University, Lithuania, 22-23 September 2020 / editors Andrius Utka, Jurgita Vaičenonienė, Jolanta Kovalevskaitė, Danguolė Kalinauskaitė. Amsterdam: IOS Press, 2020: <https://doi.org/10.3233/FAIA200631>.
10. Specific features of the spoken LLC
Due to the specifics of annotation in spoken language transcriptions, sentences begin with a lowercase letter and are not punctuated.
Compared to written language, spoken language is less cohesive; therefore, in transcribed texts one can find vocalizations (e.g. aaa, mmm), reformulated utterances and self-corrections, e.g. dau daug (‘man many’, and unfinished words, e.g. supr (= supratau) (‘understand’).
11. Abbreviations
In the LLC, the following abbreviations are used:
xxx – incomprehensible word;
XXX – proper name omitted when anonymizing the data;
X – personal name omitted when anonymizing the data;
<ee> – when this symbol appears in the position of the search word, it indicates that the word was omitted in the learner’s text, but during normalisation the search word was inserted.
Developers of the LLC
The corpus was developed by researchers from the Center of Intercultural Communication and Multilingualism as well as representatives of other departments of Vytautas Magnus University: Jūratė Ruzaitė (Research Team Coordinator), Sigita Dereškevičiūtė, Viktorija Kavaliauskaitė-Vilkinienė, Eglė Krivickaitė-Leišienė, Agnė Blažienė, Teresė Ringailienė, and Jurgita Vaičenonienė.
Web Developer: Petras Pauliūnas
Referring to the LLC
If you use material from the LLC, you should provide a reference to it, which should include the following information:
Ruzaitė, Jūratė; Dereškevičiūtė, Sigita; Kavaliauskaitė-Vilkinienė, Viktorija; Krivickaitė-Leišienė, Eglė. Lietuvių kalbos mokinių tekstynas [e-resource]. Kaunas: Vytauto Didžiojo universitetas, 2021. DOI: https://kalbu.vdu.lt/mokymosi-priemones/mokiniu-tekstynas/.
References
Del Rio I., Antunes S., Mendes A, Janssen M. Towards error annotation in a learner corpus of Portuguese. In: Proceedings of the Joint Workshop on NLP for Computer Assisted Language Learning and NLP for Language Acquisition. Umea: LiU Electronic Press; 2016. pp. 8-17.
Janssen M. TEITOK: Text-faithful annotated corpora. In: Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016), Portorož; 2016. pp. 4037-4043.
The LLC frequency lists were generated by Loïc Boizou; they were processed and finalised by Jūratė Ruzaitė.
The lists can be downloaded as .xlsx files.
They include all the word forms used in the LLC, except for proper names and foreign words. The word forms are ranked by frequency but can also be rearranged alphabetically in the downloadable .xlsx files. The lists are available for the entire corpus, for different language levels, and for the components representing different modes (spoken and written). There are two sets of frequency lists: lists based on non-normalised data and those based on normalised data (see below).
Frequency lists based on non-normalised data
The frequency lists based on non-normalised data, contain original word forms as they occur in learners’ authentic texts. Thus, these lists include a huge variety of non-existent and/or deviant forms.
Frequency list for the whole LLC
Level A1 (Written component)
Level A1 (Spoken component)
Level A1 (All texts)
Level A2 (Written component)
Level A2 (Spoken component)
Level A2 (All texts)
Level B1 (Written component)
Level B1 (Spoken component)
Level B1 (All texts)
Level B2 (Written component)
Level B2 (Spoken component)
Level B2 (All texts)
Frequency lists based on normalised data
In the LLC, normalisation was performed by using the TEITOK programme (developed by Maarten Janssen, http://www.teitok.org/), where normalisation is merged with error annotation. That is, in the process of normalisation, (a) an error type (sometimes more than one) was attributed to each word or segment in the learner text that deviates from the norm of standard Lithuanian and (b) each deviant form was corrected by minimally changing the form (but only when necessary) without changing the content of the learner text. Normalised data thus no longer contains non-existent or irregular forms and is fully searchable.
When normalising the data, it is often difficult (and sometimes even impossible) to reconstruct the learner’s intended message. In many cases, more than one interpretation of the intended meaning is possible and more than one correction for the same deviation can be provided. Thus, in the process of normalisation and error annotation, subjectivity is inevitable. Therefore, corrections in learner data have the status of hypotheses (target hypotheses), and in the LLC they do not aim to be final and indisputable. The main goal of these corrections is to make the data maximally searchable.
Frequency list for the whole LLC
Level A1 (Written component)
Level A1 (Spoken component)
Level A1 (All texts)
Level A2 (Written component)
Level A2 (Spoken component)
Level A2 (All texts)
Level B1 (Written component)
Level B1 (Spoken component)
Level B1 (All texts)
Level B2 (Written component)
Level B2 (Spoken component)
Level B2 (All texts)
Search form v.2.0, Database v.2.2 (2021-12-20 10:46)